LinkedIn 在更新服务条款之前就已抓取用户数据用于训练
LinkedIn 在更新服务条款之前就已抓取用户数据用于训练
LinkedIn 可能在未经更新其服务条款的情况下,已使用用户数据来训练 AI 模型。
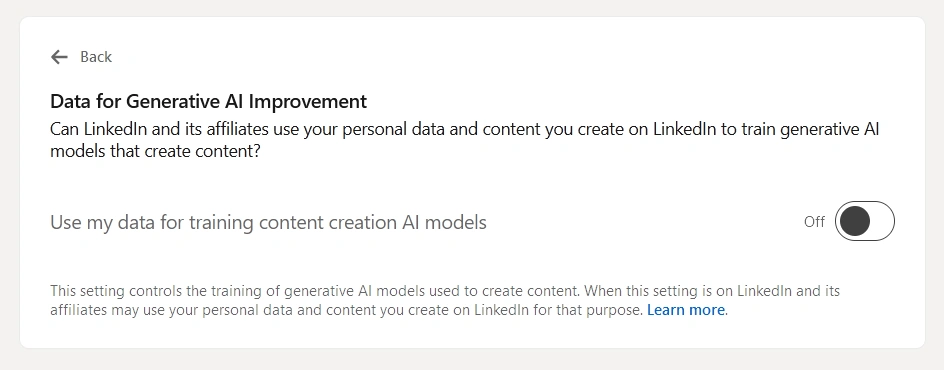
美国的 LinkedIn 用户——但不包括欧盟、欧洲经济区(EEA)或瑞士的用户,可能由于这些地区的数据隐私法规——可以在设置界面中找到一个“选择退出”开关,表明 LinkedIn 会抓取个人数据用于训练“内容创建 AI 模型”。这一开关并非新功能。但正如 404 Media 首次报道的那样,LinkedIn 起初并未更新其隐私政策以反映这种数据使用。
虽然服务条款现在已经更新,但通常在做出诸如将用户数据用于新的用途等重大变更之前,就应该提前更新条款。这种做法通常是为了让用户有机会对账户进行更改或决定是否继续使用该平台。然而,这次似乎并非如此。
那么 LinkedIn 正在训练哪些模型呢?公司在问答中表示,是其自有模型,包括用于撰写建议和帖子推荐的模型。但 LinkedIn 也表示,其平台上的生成式 AI 模型可能由“其他提供商”训练,例如其母公司微软。
问答中写道:“与 LinkedIn 上的大多数功能一样,当您使用我们的平台时,我们会收集并使用(或处理)有关您使用该平台的数据,包括个人数据。” “这可能包括您使用生成式 AI(用于创建内容的 AI 模型)或其他 AI 功能的情况、您的帖子和文章、您使用 LinkedIn 的频率、您的语言偏好,以及您可能向我们团队提供的任何反馈。我们根据隐私政策使用这些数据,以改进或开发 LinkedIn 服务。”
LinkedIn 之前说 ,它使用“隐私增强技术,包括编辑和删除信息,来限制用于生成式 AI 训练的数据集中的个人信息。”
要退出 LinkedIn 的数据抓取,进入桌面版 LinkedIn 设置菜单中的“数据隐私”部分,点击“用于改进生成式 AI 的数据”,然后关闭“使用我的数据来训练内容创建 AI 模型”选项。你也可以尝试通过此表单更全面地选择退出,但 LinkedIn 提醒,任何选择退出都不会影响已经进行的训练。
非营利组织 Open Rights Group(ORG)已呼吁英国信息专员办公室(ICO),即英国的数据保护权独立监管机构,调查 LinkedIn 和其他默认使用用户数据进行 AI 训练的社交网络。本周早些时候,Meta 宣布在与 ICO 合作简化选择退出流程后,将重新启动抓取用户数据用于 AI 训练的计划。
“LinkedIn 是最新一家在未经用户同意的情况下处理我们数据的社交媒体公司,”ORG 的法律与政策官员 Mariano delli Santi 在一份声明中表示。“选择退出的模式再次证明完全不足以保护我们的权利:公众不可能监控和追踪每个决定使用我们数据来训练 AI 的在线公司。选择加入同意不仅是法律要求,更是常识性需求。”
负责监督 GDPR(欧盟通用数据保护条例)合规性的爱尔兰数据保护委员会(DPC)告诉声称,LinkedIn 上周通知他们,今天将发布对全球隐私政策的澄清。
DPC 的一位发言人表示:“LinkedIn 告知我们,政策将包括为不希望其数据用于训练内容生成 AI 模型的成员提供选择退出设置。” “这一选择退出功能对欧盟/欧洲经济区成员不可用,因为 LinkedIn 目前并未使用欧盟/欧洲经济区成员的数据来训练或微调这些模型。”
对训练生成式 AI 模型的数据需求日益增长,导致越来越多的平台将用户生成的内容重新用于其他用途。一些平台甚至开始通过这些内容获利——Tumblr 的母公司 Automattic、Photobucket、Reddit 和 Stack Overflow 等网络正在向 AI 模型开发者许可数据。
并不是所有平台都让用户轻松选择退出。当 Stack Overflow 宣布将开始许可内容时,几位用户删除了他们的帖子以示抗议——但这些帖子随后被恢复,账户也被暂停。