OpenAI 终于“开门”了,迟到五年的 GPT-oss 亮相
DeepFlow·深流API(https://ai.gptcard.cn/) 现已支持 OpenAI 最新模型推理 gpt-oss-120b、gpt-oss-20b
北京时间 2025 年 8 月 5 日,在科技圈调侃了五年之后,那个名字里带着“Open”却一直闭门不出的 OpenAI,终于打开了久违的大门。继 2019 年 GPT-2 后,OpenAI 首次真正意义上的开源模型系列 GPT-oss 正式发布,包括旗舰级 GPT-oss-120b 和消费级 GPT-oss-20b 两款重量级产品。
说起来,自从 GPT-3 闭源之后,科技圈就流传着这样的段子:“OpenAI 最大的谎言就是它的名字——既不 open,也越来越不像非营利的 AI 研究机构。” 毕竟这几年间 OpenAI 一直采取封闭式战略,依靠 API 调用收费赚得盆满钵满,年收入甚至突破 130 亿美元。而 CEO Sam Altman 曾公开承认:“在开源问题上,我们站在了历史的错误一边。”这番坦诚的自嘲,或许真要感谢 DeepSeek 和阿里 Qwen 等开源先锋——正是它们逼迫这家估值 3000 亿美元的独角兽重新审视自身战略。
GPT-oss 到底“开”了什么门?
这次 OpenAI 提出的“open-weight”概念意味着:模型权重完全公开,开发者、企业用户都可以下载、修改、商用,遵循宽松的 Apache 2.0 许可。这种真正的开源模式,足以让生态圈为之振奋。
大的很大,小的够用
- GPT-oss-120b 拥有约 1170 亿参数,采用混合专家(MoE)架构,每个 token 仅激活 51 亿参数,搭配创新的 MXFP4 4位量化技术,能在单个 Nvidia H100 GPU(80GB)上顺畅运行。性能甚至超越自家闭源的 o3-mini,与旗舰模型 o4-mini 不相上下。
- GPT-oss-20b 只有约 210 亿参数,每个 token 激活 36 亿参数,甚至能在 16GB 内存的普通笔记本电脑上运行,堪称消费级硬件上的最强大脑,完全能匹敌甚至超越闭源版 o3-mini 的表现。
性能:开源阵营的新标杆
在多个基准测试上,GPT-oss 系列表现惊艳。
- 编程能力:GPT-oss-120b 在 Codeforces 编程竞赛等场景下表现强劲,接近 GPT-4 的编程能力。
- 数学推理:AIME 2024 和 2025 的测试中,甚至 GPT-oss-20b 的表现也超出预期,优于同量级闭源产品。
- 通用知识理解:在 MMLU 基准测试中,两款模型展现出宽泛的知识储备和强大的推理能力。
- 工具调用与链式思维:原生支持 agentic reasoning,模型可调用外部工具、执行 Python 代码,极大地拓展了应用场景。
| gpt-oss-120b | gpt-oss-20b | OpenAI o3 | OpenAI o4-mini | |
|---|---|---|---|---|
| Reasoning & knowledge | ||||
| MMLU | 90.0 | 85.3 | 93.4 | 93.0 |
| GPQA Diamond | 80.1 | 71.5 | 83.3 | 81.4 |
| Humanity’s Last Exam | 19.0 | 17.3 | 24.9 | 17.7 |
| Competition math | ||||
| AIME 2024 | 96.6 | 96.0 | 95.2 | 98.7 |
| AIME 2025 | 97.9 | 98.7 | 98.4 | 99.5 |
Codeforces 编程竞赛 Elo 分数对比
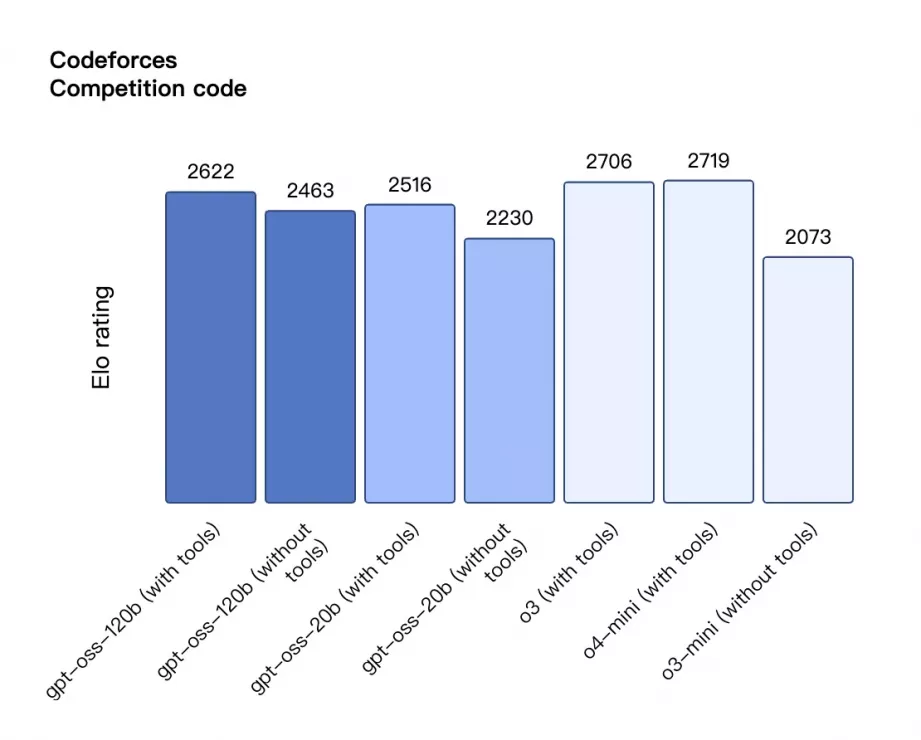
柱状图对比 gpt-oss 与 OpenAI 闭源模型在 Codeforces 编程竞赛任务中的 Elo rating 表现。gpt-oss-120b 使用工具时得分 2622,略低于 o3(2706)与 o4-mini(2719),高于不使用工具时的 gpt-oss-120b(2463);gpt-oss-20b 使用工具时为 2516,不使用工具时为 2230,优于 o3-mini(2073)。显示出 gpt-oss 模型在代码生成任务中的较强能力,但略逊于高端闭源模型。
Humanity’s Last Exam – 跨学科专家题准确率
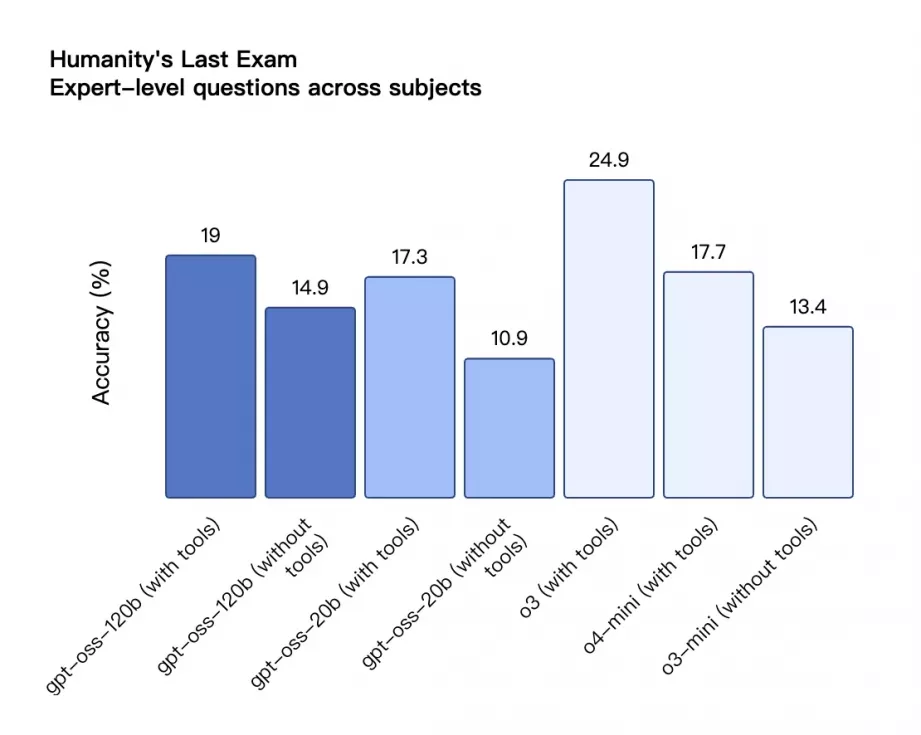
柱状图对比不同模型在 Humanity’s Last Exam(人类最后的考试)任务下的准确率,包括使用工具与否的两种模式。gpt-oss-120b 使用工具时得分最高(19%),略高于 gpt-oss-20b(17.3%),但都低于 o3(24.9%),显著优于 o3-mini 与不带工具模式。
HealthBench Hard – 挑战性医疗对话得分
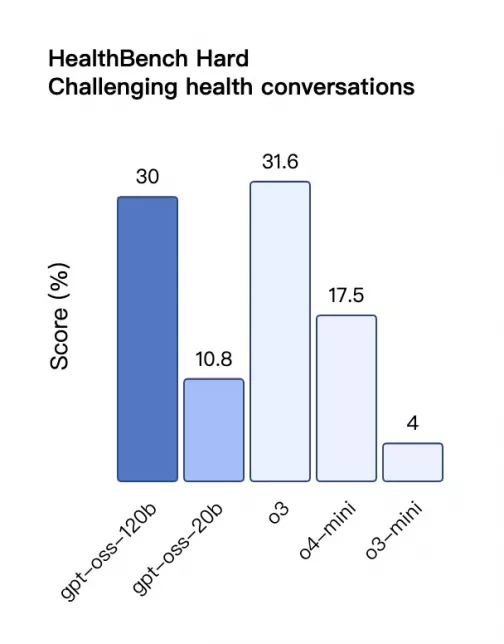
柱状图显示各模型在 HealthBench Hard 医疗对话任务中的表现。gpt‑oss‑120b(工具模式) 得分约为 **30%**,略低于 o3 的 **31.6%**,明显高于 gpt‑oss‑20b(10.8%)、o4‑mini(17.5%)与 o3‑mini(4%)。显示出带工具的 gpt‑oss‑120b 在医疗对话中具备较强应对能力。
AIME 2025 工具增强数学任务准确率
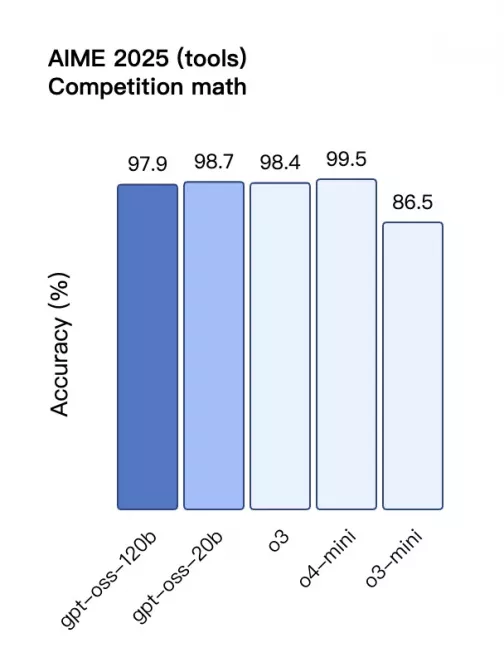
柱状图显示在 AIME 2025 数学竞赛类题目中开启工具模式下的准确率。gpt‑oss‑20b(工具) 的表现为 **98.7%**,略高于 gpt‑oss‑120b(97.9%),接近 o4‑mini(99.5%)与 o3(98.4%),远高于 o3‑mini(86.5%)。
MMLU 综合学科问答准确率对比
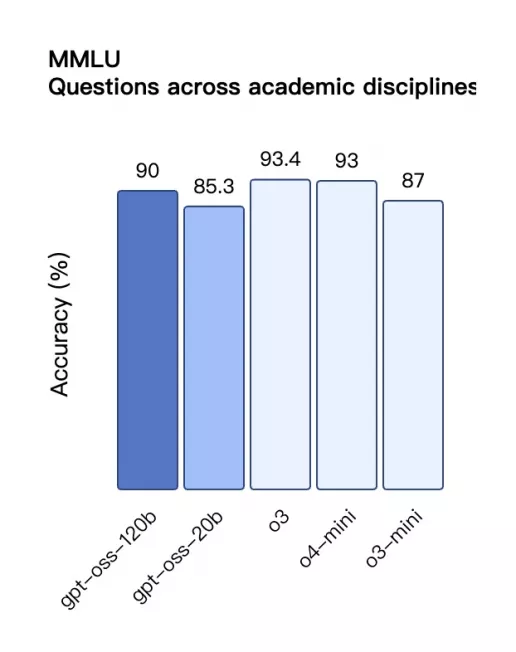
柱状图展示 gpt‑oss 与 OpenAI 闭源模型在 MMLU 综合学科任务上的准确率:gpt‑oss‑120b 得分约为 90%,略低于 o3(93.4%)和 o4‑mini(93%),但仍优于 o3‑mini(87%);gpt‑oss‑20b 得分约为 **85.3%**。
GPQA Diamond 博士级科学问答任务准确率
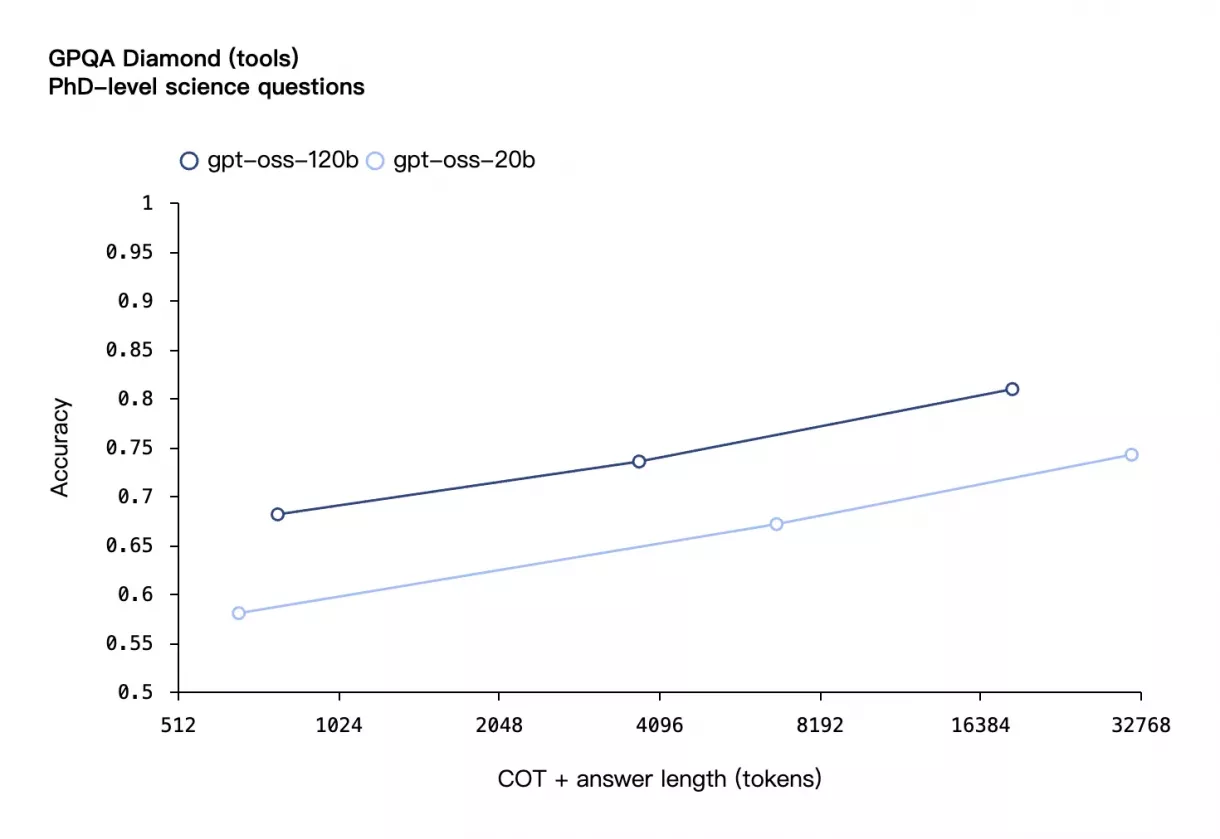
折线图显示 gpt‑oss‑120b 与 gpt‑oss‑20b 在 GPQA Diamond 博士级科学问答任务中的表现随 COT + 答案长度变化。随着 tokens 长度从较短增加至 16384,准确率逐步上升:gpt‑oss‑120b 从约 68% 提升至 **约 81%**,gpt‑oss‑20b 则从约 58% 提升至 **约 74%**,gpt‑oss‑120b 全程领先。
技术亮点:不只是参数堆叠的艺术
两款模型都展现了OpenAI在架构设计上的深厚功力:
高效的注意力机制:采用交替的密集和局部带状稀疏注意力模式,配合分组多查询注意力(组大小为8),大幅提升推理效率。
灵活的推理能力:支持链式思维(Chain-of-Thought)推理,可根据任务复杂度自适应调整推理深度,避免在简单任务上浪费计算资源。
完善的工具生态:原生支持网页搜索、Python代码执行等工具调用,内置function calling能力,是构建AI Agent的理想选择。
安全考量不放松
虽说权重完全开放,OpenAI 依然保持谨慎态度。发布前,大量内部安全测试和第三方审核相继完成,确保 GPT-oss 即便经过恶意微调,也未触及生物化学、网络安全等领域的高风险能力阈值。此外,OpenAI 还特别设立了总奖金高达 50 万美元的红队挑战赛,以确保生态的安全性。
为什么 OpenAI 此时重新开源?
这次重新“开门”,不仅是 OpenAI 战略上的及时转向,更反映出市场环境的巨大变化。
过去几年,以DeepSeek、Qwen 为代表的新兴开源势力迅猛崛起,Meta 的 Llama 系列更是不断刷新开源性能标杆。开放、可控、本地部署的趋势成为主流,闭源模式开始逐渐被市场所摒弃。
OpenAI 此次重新拥抱开源,是对市场需求的回应,也是为修正自身战略偏差。正如 Sam Altman 所说:“我们必须重新规划开源战略,因为历史已经证明闭源之路并非通向成功的唯一途径。”
迟到的开源,恰逢其时
尽管 OpenAI 这次开门的动作晚了五年,但正如业界一位开发者所调侃的那样:“虽然迟到,但总比永远不来要好。”GPT-oss 的发布,为开源社区带来了高性能模型的全新标杆,也标志着 AI 行业重新回归开放与竞争。
对广大开发者和企业来说,这无疑是一个巨大利好。如今,“OpenAI”终于名副其实地打开了大门,允许你下载权重,亲手体验这个估值 3000 亿美元的公司所创造的 AI 究竟能做到什么。
或许,OpenAI 终于明白,“Open”从来不是弱点,而是通向未来的最佳路径。这一次,“开放”真正回归了 OpenAI。
所有业务可以在https://chatshare.info查看,页面更加简洁,直达需求!如果有其他问题,请添加站长微信咨询哦~