GPT-4o通过整合文本、音频和视觉实现人性化的AI交互
GPT-4o通过整合文本、音频和视觉实现人性化的AI交互
OpenAI推出了其新的旗舰模型GPT-4o,它无缝整合了文本、音频和视觉输入与输出,有望提高机器交互的自然性。现在Plus用户可以直接使用GPT-4o,关于如何开通Plus,可以使用WildCard平台。
GPT-4o中的”o”代表”omni”(全方位),旨在满足更广泛的输入和输出模式。OpenAI宣布:”它接受任何文本、音频和图像的组合作为输入,并生成文本、音频和图像输出的任何组合。”WildCard也支持Claude, Midjourney, Adobe, Patreon, Midjourney, OF, X等的订阅。
用户可以期待与人类对话速度一样快的232毫秒的响应时间,平均响应时间为320毫秒,令人印象深刻。
开创性的能力
GPT-4o的推出标志着与其前身相比的一大飞跃,通过单一神经网络处理所有输入和输出。这种方法使模型能够保留在早期版本中使用的独立模型管道中丢失的关键信息和上下文。
在GPT-4o之前,”语音模式”可以处理GPT-3.5的2.8秒延迟和GPT-4的5.4秒延迟的音频交互。之前的设置涉及三个不同的模型:一个用于将音频转录为文本,另一个用于文本响应,第三个用于将文本转换回音频。这种分割导致了语气、多个说话者和背景噪音等细微差别的丢失。
作为一个集成解决方案,GPT-4o在视觉和音频理解方面有显著改进。它可以执行更复杂的任务,如和声歌曲、提供实时翻译,甚至生成带有表现元素的输出,如笑声和歌声。其广泛能力的例子包括准备面试、即时翻译语言以及生成客户服务响应。
Superintelligent的创始人兼首席执行官Nathaniel Whittemore评论道:”产品公告本质上比技术公告更具分歧性,因为在实际与产品互动之前很难判断产品是否真正不同。特别是当涉及人机交互的不同模式时,对其有用性的看法会更加多样化。话虽如此,没有宣布GPT-4.5或GPT-5的事实也分散了人们对这是一个原生多模态模型的技术进步的注意力。它不是一个带有语音或图像附加功能的文本模型;它是一个多模态令牌输入,多模态令牌输出。这开启了大量用例,需要一些时间才能渗透到人们的意识中。”
性能和安全性
GPT-4o在英语文本和编码任务方面与GPT-4 Turbo的性能水平相当,但在非英语语言方面明显优于后者,使其成为一个更具包容性和通用性的模型。它在推理方面设定了一个新的基准,在0-shot COT MMLU(一般知识问题)上获得了88.7%的高分,在5-shot no-CoT MMLU上获得了87.2%的高分。
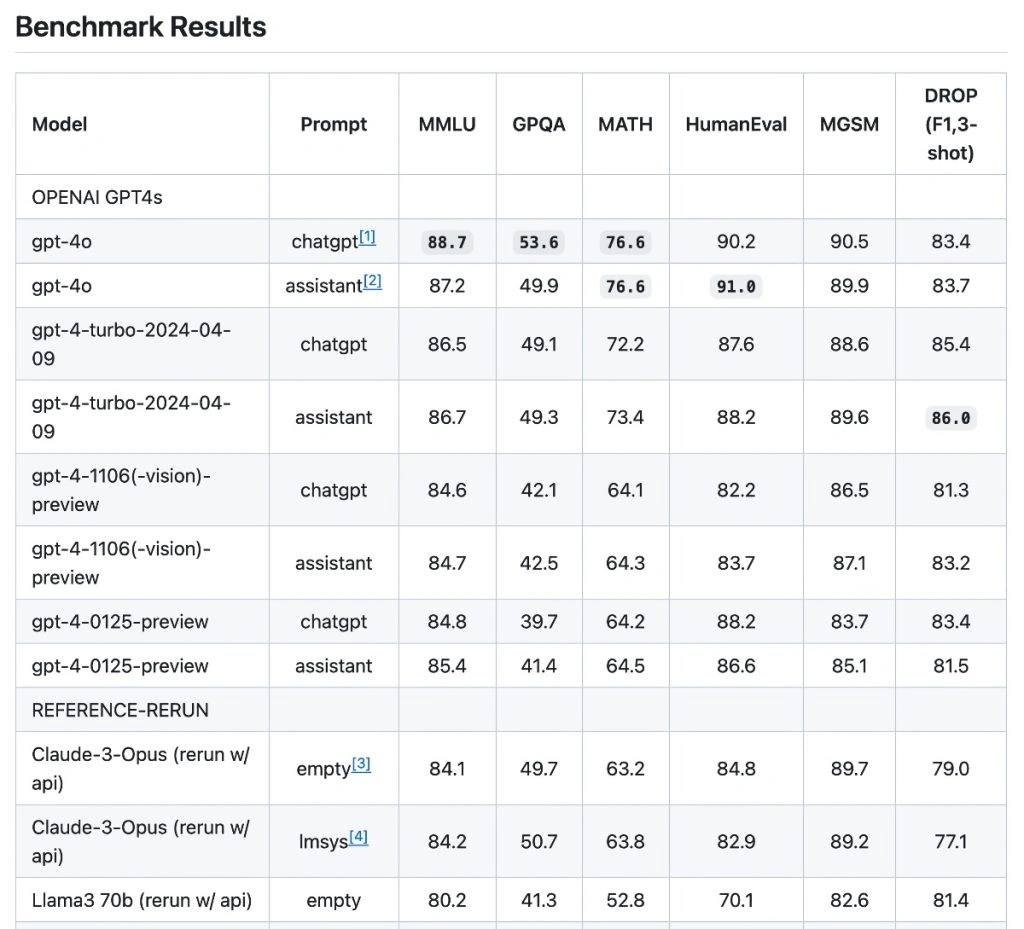
该模型在音频和翻译基准测试中也表现出色,超过了之前最先进的模型,如Whisper-v3。在多语言和视觉评估中,它展示了卓越的性能,增强了OpenAI的多语言、音频和视觉能力。
OpenAI通过设计将强大的安全措施纳入GPT-4o,结合过滤训练数据的技术,并通过训练后的保障措施完善行为。该模型已通过准备框架进行评估,并符合OpenAI的自愿承诺。在网络安全、说服力和模型自主性等领域的评估表明,GPT-4o在任何类别中都没有超过”中等”风险级别。
进一步的安全评估涉及广泛的外部红队测试,有70多名来自社会心理学、偏见、公平和错误信息等各个领域的专家参与。这种全面的审查旨在减轻GPT-4o新模式带来的风险。
可用性和未来集成
从今天开始,GPT-4o的文本和图像功能可在ChatGPT中使用,包括免费版和Plus用户的扩展功能,但是免费版的每天仅仅只有几次的试用。未来几周内,由GPT-4o驱动的新语音模式将在ChatGPT Plus中进行Alpha测试。
开发人员可以通过API访问GPT-4o进行文本和视觉任务,与GPT-4 Turbo相比,它的速度提高了一倍,价格降低了一半,速率限制也得到了提高。
OpenAI计划通过API将GPT-4o的音频和视频功能扩展到一组精选的可信合作伙伴,预计在不久的将来会进行更广泛的推广。这种分阶段发布策略旨在确保在公开提供全部功能之前进行彻底的安全性和可用性测试。
Whittemore解释说:”他们免费向所有人提供这个模型,并使API价格降低50%,这一点非常重要。这大大提高了可访问性。”
OpenAI邀请社区反馈,以不断完善GPT-4o,强调用户输入在识别和弥合GPT-4 Turbo可能仍然优于GPT-4o的差距方面的重要性。