Hugging Face 推出 Idefics2 视觉语言模型
Hugging Face 公司宣布推出 Idefics2,这是一个多功能模型,能够理解和生成基于图像和文本的文字回复。该模型为回答视觉问题、描述视觉内容、根据图像创作故事、文档信息提取,甚至根据视觉输入执行算术运算树立了新的标杆。
Idefics2 仅有 80 亿个参数,其开放许可证(Apache 2.0)带来的多功能性以及显著增强的光学字符识别(OCR)功能,使其超越了前代产品 Idefics1。
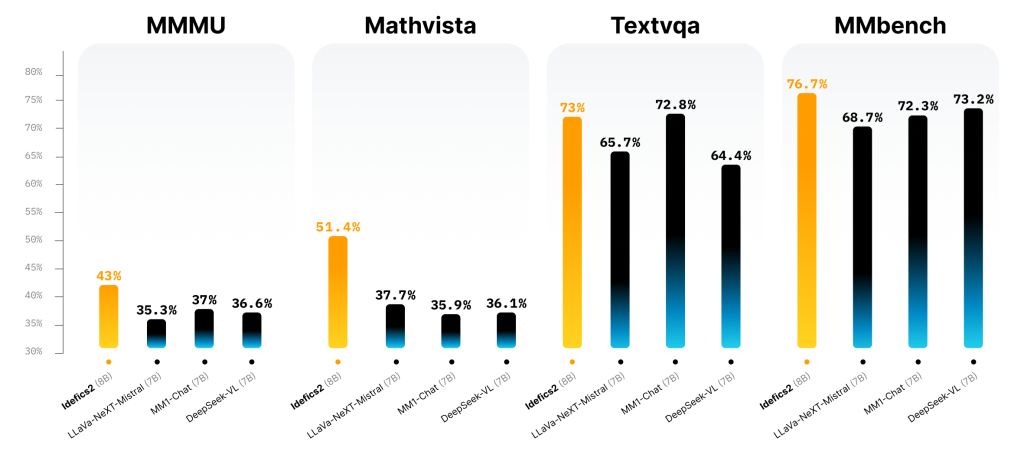
该模型不仅在可视化问题解答基准测试中表现出色,而且在与 LLava-Next-34B 和 MM1-30B-chat 等规模更大的同类产品的竞争中也毫不逊色:
Idefics2 最吸引人的地方在于它从一开始就与 Hugging Face 的 Transformers 相集成,从而确保可以轻松地对各种多模式应用进行微调。对于那些急于深入研究的人,Hugging Face Hub 上提供了可供实验的模型。
Idefics2 的一个突出特点是其全面的训练理念,它融合了公开可用的数据集,包括网络文档、图像字幕对和 OCR 数据。此外,它还引入了被称为 “熔炉 “的创新微调数据集,将 50 个精心策划的数据集整合在一起,用于多方面的会话训练。
Idefics2 采用了一种精细的图像处理方法,保持了原始分辨率和长宽比–这与计算机视觉领域传统的大小调整规范大相径庭。它的架构明显得益于先进的 OCR 功能,能够熟练地转录图像和文档中的文本内容,在解读图表和数字方面的性能也得到了提高。
简化视觉特征与语言主干的整合,标志着 Idefics2 与其前身架构的转变,采用学习型感知器池和 MLP 模式投影增强了 Idefics2 的整体功效。
视觉语言模型的这一进步为探索多模态交互开辟了新途径,Idefics2 将成为该领域的基础工具。它的性能提升和技术创新凸显了将视觉和文本数据结合起来,创建复杂的、能感知上下文的人工智能系统的潜力。



如果需代充ChatGPT PLUS、购买镜像站激活码,或其他问题,请添加站长微信咨询哦~